
해시 개념
- 배열을 가지고 연락처를 구현할 때 미우 비효율적 (O(N))
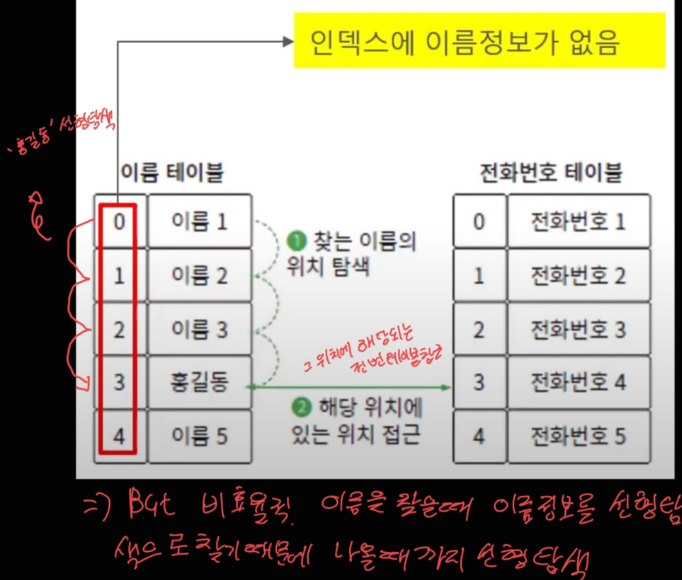
- 해시 함수를 이용하여 연락처를 구현하면 훨씬 효율적 (O(1))


해시 함수란?
⇒임의의 키를 해시 테이블의 인덱스로 변경해주는 함수
해시 테이블의 크기가 N이라면 해시함수는 0~(N-1)사이 값을 반환 해야함.

충돌 : 서로 다른 키를 해시함수에 넣었을 때 , 동일한 인덱스를 반환하는것.
⇒ 따라서 이 충돌을 최소화 할수록 좋은 해시함수
나눗셈법
⇒ 입력값을 테이블의 크기로 나누고 나머지를 테이블의 주소로 사용.
주소 = 입력값 %테이블의 크기.
일반적으로 나눗셈법으로 구현된 해시 함수고 테이블 내 공간을 효율적으로 사용하기 위해서는 테이블의 크기를 소수로 정하는 것이 좋다고 알려짐.
해시 충돌
⇒ 서로 다른키에 대해 해시 함수 결괏값이 같은 경우 충돌이 발생함.
해결법!
- 체이닝
⇒ 충돌 발생 시, 해당 버킷에 링크드리스트로 데이터 연결함.
주의점 : 특정 버킷에 데이터가 N개인 경우 원하는 값을 찾는데 O(N)이 걸릴수 있음

⇒B C K 가 해시함수를 적용했을 때 해시테이블의 같은 곳(3 번)을 가리키고 있을 때 링크드 리스트로 데이터를 연결함.
해시를 사용해야 하는 경우
1. 키 - 값 쌍으로 연관된 데이터가 존재하며, 해당 값에 대한 접근이 빈번한 경우
EX) 사전(단어를 검색하여 뜻을 찾음), 연락처 (이름을 검색해서 번호를 찾음 ⇒이름 : 키 , 전화번호 : 값)
⇒ 어떤 데이터를 키 OR 값으로 설정해야 할지 정하는 것이 중요
2. 중복되지 않는 키를 사용하는 경우
⇒ 만일 중복된 키를 사용하면 ….
ex) 동일한 키를 이용해 데이터를 넣는다 치면.
키1 →값1
키1 →값2
이렇게 두개가 따로 들어가 있는것이 아닌
키1 → 값2 이대로 키1의 값이 덮어 씌워져 버린다.

EX) 학번, 집주소, 주민번호 등..
해시 사용하는 예시들
학생 정보 관리 시스템
⇒키 : 학생 ID , 값 : 성적
1. ID - 점수 한개
map은 해시가 아님. 이진 탐색 트리를 활용한 것.
매번 키 순으로 데이터가 정렬 됨 O(logN)
=> 따라서 TLE발생할 수 있다.
키 값 정렬이 필요 하지 않은데, map을 사용하면 시간초과 발생.
따라서 해시 문제는 map이 아니라 unordered_map을 사용해서 풀어야한다.
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
int main() {
unordered_map<string, string> students;
// 학생 데이터 삽입
students["12345"] = "A";
students["67890"] = "B";
students["54321"] = "A+";
string student_id = "12345";
if (students.find(student_id) != students.end()) {
// 학생 ID가 존재하면 성적을 출력
cout << "학생 ID: " << student_id << "\n";
cout << "성적: " << students[student_id] << "\n"; // 해당 학생의 성적 출력
// 출력값: 성적: A
} else {
cout << "학생 정보를 찾을 수 없습니다.\n";
}
return 0;
}2. ID - 점수 여러개
#include <iostream>
#include <unordered_map>
#include <vector>
#include <string>
#include <numeric> // std::accumulate를 사용하기 위해 필요
using namespace std;
// 특정 학생의 점수를 출력하는 함수
void print_scores(const unordered_map<string, vector<int>>& student_scores,
const string& name) {
// 학생이 존재하는지 확인
auto it = student_scores.find(name);
if (it != student_scores.end()) {
cout << name << "의 점수: ";
// 학생의 모든 점수를 출력
//it->first ==> 키
//it->second ==>값
//따라서 아래 코드는 키에 따른 모든 점수를 보여준다
for (int score : it->second) {
cout << score << " ";
}
cout << endl;
} else {
// 학생이 존재하지 않을 경우 메시지 출력
cout << name << "의 점수를 찾을 수 없습니다." << endl;
}
}
// 특정 학생의 평균 점수를 계산하고 출력하는 함수
void print_average_score(const unordered_map<string, vector<int>>& student_scores, const string& name) {
// 학생이 존재하는지 확인
auto it = student_scores.find(name);
if (it != student_scores.end()) {
const vector<int>& scores = it->second; // 학생의 점수 목록을 참조
// 평균 점수 계산
// accumulate 함수는 주어진 범위의 요소를 모두 더하는 함수입니다.
// 첫 번째 인자는 시작 반복자,
//두 번째 인자는 끝 반복자,
//세 번째 인자는 초기값입니다.
// 이 경우 scores 벡터의 모든 요소를 더하고 초기값 0.0에서
//시작하여 결과를 double로 반환합니다.
// accumulate 함수의 시간 복잡도는 O(n)입니다.
//여기서 n은 벡터의 요소 개수입니다.
double average = accumulate(scores.begin(), scores.end(), 0.0) / s cores.size();
cout << name << "의 평균 점수: " << average << endl;
} else {
// 학생이 존재하지 않을 경우 메시지 출력
cout << name << "의 점수를 찾을 수 없습니다." << endl;
}
}
int main() {
//키: 학생이름 값: 여러 점수를 넣기위한 vector 공간
unordered_map<string, vector<int>> student_scores;
//push_back : vector의 마지막에 새로운 원소를 추가
student_scores["Alice"].push_back(90);
student_scores["Alice"].push_back(85);
//엘리스 점수들 추가
student_scores["Bob"].push_back(78);
student_scores["Bob"].push_back(82);
student_scores["Bob"].push_back(88);
//밥 점수들 추가
print_scores(student_scores, "Alice");
print_average_score(student_scores, "Alice");
print_scores(student_scores, "Bob");
print_average_score(student_scores, "Bob");
print_scores(student_scores, "Charlie");
print_average_score(student_scores, "Charlie");
return 0;
}
/*
출력 결과:
Alice의 점수: 90 85
Alice의 평균 점수: 87.5
Bob의 점수: 78 82 88
Bob의 평균 점수: 82.6667
Charlie의 점수를 찾을 수 없습니다.
Charlie의 점수를 찾을 수 없습니다.
*/
문자열 내 빈도수 확인
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
int main() {
// 문자열 내 각 문자의 빈도를 저장할 unordered_map 선언
unordered_map<char, int> frequency;
// 분석할 문자열
string str = "hello world";
// 문자열의 각 문자를 순회하면서 빈도를 계산
for (char ch : str) {
frequency[ch]++;
}
// 각 문자의 빈도 출력
for (const auto& pair : frequency) {
cout << pair.first << ": " << pair.second << "\n";
}
// 출력값:
// h: 1
// e: 1
// l: 3
// o: 2
// : 1
// w: 1
// r: 1
// d: 1
return 0;
}
출처
[지금 무료] 코딩 테스트 합격자 되기 - C++ 강의 | dremdeveloper - 인프런
dremdeveloper | 코딩 테스트 합격을 위한 C++ 강의, 책 없이도 가능! 저자와 직접 소통 가능한 커뮤니티 제공!, [사진]여기에 문의 하세요https://open.kakao.com/o/gX0WnTCf📘 코딩 테스트 합격자 되기 - C++편
www.inflearn.com
'Algorithm > 코딩테스트_합격자되기_인프런 _스터디' 카테고리의 다른 글
| [Step 5] 집합 (0) | 2024.08.11 |
|---|---|
| [Step 4] 트리 (0) | 2024.08.03 |
| [Step 2] 스택/큐 (2) | 2024.07.20 |
| [Step 1.5] 코딩 테스트에서 꼭 알아야 할 C++ 문법 (0) | 2024.07.18 |
| [Step 1] 시간 복잡도 (0) | 2024.07.11 |